docs.moe-sovereign.org ↗
Full documentation: architecture, API reference, integration guides, and administration manual.
Open Source · Apache 2.0 · Air-Gap Ready · Federated Knowledge · Public Release: April 13, 2026
MoE Sovereign is a template-based Multi-Model Orchestrator that runs entirely on your own hardware. Requests are classified, routed to specialised LLM experts, enriched by a knowledge graph and real-time web search, then synthesised by a Judge model — all without sending data to external APIs. Community knowledge bundles enable Federated Knowledge Sync where every deployment enriches the collective intelligence.
curl -sSL https://raw.githubusercontent.com/h3rb3rn/moe-sovereign/main/install.sh | bash
Resources
Documentation, source code, and community tools for getting started with your own MoE Sovereign deployment.
Full documentation: architecture, API reference, integration guides, and administration manual.
User self-service: create API keys, configure Claude Code profiles, assign expert templates, view token usage.
Open WebUI with a direct connection to the MoE API. All model IDs and expert modes available immediately.
OpenAI-compatible and Anthropic Messages API endpoint. Per-user token limits enforced server-side.
Federated knowledge exchange: share and import knowledge graph entries across sovereign MoE instances.
EU-sovereign compliance data platform: catalog, approval workflows, lineage, versioning, and drift detection for regulated deployments.
German version of the project website with full project description.
This page — the international English version of the project.
The Concept
Instead of a single massive model on an expensive GPU, many specialized models are coordinated — each running on the hardware best suited for it.
Modern Large Language Models (LLMs) like GPT-4 or Claude require significant investments in GPU hardware for self-hosting — and create a permanent cloud dependency with corresponding privacy risks. For businesses, research institutions, and privacy-conscious users, both paths are often not an ideal option.
MoE Sovereign distributes inference across a cluster of nodes. Each request is analyzed by an intelligent planner, routed to the appropriate expert models, and the results are synthesized by a merger model. The outcome: for structured knowledge and research tasks, on par with smaller cloud models — with full data control as an option and at a fraction of the running cost.
Privacy by Design is an architectural option, not a constraint: The inference backends can be Ollama instances on your own hardware, but equally well Claude API endpoints, your own enterprise AI hubs, or cloud inference services. The MoE system is the routing layer — it is decoupled from the hardware.
The API is fully OpenAI-compatible and implements the Anthropic Third-Party Inference Gateway spec, so existing tools like Open WebUI, Claude Desktop, Claude Cowork, Claude Code, or any OpenAI SDK integration work without modification.
Knowledge bundles enable structured exchange of domain-specific knowledge graphs between independent deployments. Each instance remains autonomous and offline-capable; shared bundles enrich the local graph without transferring source data or proprietary information.
As an option: all data stays on your own infrastructure. Not a single API call leaves your network — if you want.
Equally usable as a routing layer in front of cloud services: Claude, Gemini, Azure OpenAI, or your own enterprise AI hubs.
Tesla K80 to RTX 3060: retired enterprise hardware and affordable consumer GPUs are sufficient for distributed inference.
Fully licensed under Apache 2.0. No vendor lock-in, no hidden costs, no proprietary stack.
Token Costs
Not every question needs a 100-billion-parameter model. MoE Sovereign classifies requests heuristically and routes them to the cheapest model that can solve the task — without LLM overhead for the classification itself.
Heuristic complexity routing classifies every request without an LLM call into three tiers — loading expensive models only when truly needed.
Internal benchmark result (reference setup): In the AIHUB H200 benchmark (proprietary, internal evaluation framework), the M10 Council template (8 experts on legacy hardware with gpt-oss:120b + qwen-3.5:122b) scored 9/9 (100 %) — fully self-hosted, 0 cloud API calls. In the demo reference deployment, Claude Code using the
moe-orchestrator-agent-orchestratedprofile delegates over 80 % of sub-tasks to self-hosted experts.
Capabilities
MoE Sovereign ships with all components needed for a production-ready AI infrastructure.
Drop-in replacement for OpenAI endpoints and Anthropic Messages API. Every compatible tool works without code changes.
Full Anthropic Third-Party Inference Gateway compatibility.
Claude Desktop and Claude Cowork route all inference through your
MoE Sovereign cluster — no prompt ever leaves your own infrastructure.
One-command setup via scripts/setup-claude-desktop.sh.
Specialized LLMs for law, medicine, code, mathematics, translation, security, vision and more — coordinated by a Judge model with two-tier escalation.
Deterministic calculations via AST-whitelist: math, date arithmetic, unit conversion, network tools, code review, file generation — 100% accuracy, zero hallucination.
Neo4j-based knowledge graph with 2-hop traversal, automatic ingest via Kafka, and feedback integration. Corrective RAG Gate (Yan et al. 2024): relevance scoring filters low-signal entities before injection. CAG Compliance Layer (Chan et al. 2024): BAIT/VAIT/DORA/KRITIS texts injected deterministically — no retrieval latency, no coverage gaps.
ChromaDB semantic cache, Valkey plan cache, GraphRAG cache, and performance scores reduce latency and GPU load.
SearXNG meta-search engine without tracking for research queries — fully self-hosted, no external search requests.
API keys, token budgets, Claude Code profiles, and expert templates configurable per user — via admin UI or REST API.
Prometheus metrics, 5 pre-built Grafana dashboards, real-time pipeline logs via WebSocket in the admin UI.
LCARS-style status dashboard with a proactive watchdog alert loop, live node health (15 s polling), email escalation with per-alert cooldown, cross-session mission context with per-template system-prompt injection, and hot-reloadable thresholds — no container restart required.
Rule-based request classification (trivial/moderate/complex) without an LLM call — deliberately non-learned, and therefore fully transparent, reproducible and free of black-box decisions. Saves up to 80% of pipeline costs for simple queries.
Feedback (rating 1–5) flows into expert performance scores and few-shot examples — the system learns from mistakes automatically.
Image, screenshot, and document analysis via Base64 input through multimodal Tier-2 expert models.
Asynchronous background processing: GraphRAG ingest, request audit log, and feedback processing decoupled from the HTTP path.
Stochastic expert scoring via Beta distribution instead of static Laplace estimates. Natural exploration of underutilized experts without cold-start problems.
Past corrections are stored as Neo4j nodes and automatically injected as context into expert prompts when similar queries arise.
Automatic budget computation per model context window. Per-template configurable history compression with GraphRAG as long-term memory.
Tier-2 Semantic Memory via ChromaDB: conversation turns are embedded as vectors and retrieved on demand via direct numpy cosine ranking (no HNSW approximation error). The effective context window extends well beyond any native LLM limit — model-agnostic and without additional token cost at inference time.
After each synthesis a gap detector checks completeness. Unresolved questions trigger a focused follow-up round automatically — no user intervention, up to 3 agentic iterations per request.
The generate_pptx MCP tool creates fully formatted
presentations directly from the chat and delivers a signed download
link — no export step, no manual authoring required.
In the admin UI, individual expert templates and CC profiles can be checkbox-selected for targeted export — no need to export the full set every time.
SSRF protection for outbound URL requests, rate limiting at API level, and container hardening (read-only filesystem, no-new-privileges, restricted capabilities). Defense-in-depth against common attack vectors even in self-hosted deployments.
OpenLineage events flow into an embedded Marquez server; the
/catalog admin page aggregates Marquez datasets, Neo4j
knowledge domains, and lakeFS repositories into a single searchable,
source-filterable table — Foundry-inspired cross-source browsing
without leaving the admin UI.
Every external knowledge bundle is staged on a lakeFS branch
pending/<tag>-<ts> instead of being written straight
into Neo4j. Admins review pending imports on /approval and
decide with one click: approve (Neo4j MERGE + lakeFS merge to main)
or reject (branch delete). Explicit gate before any write hits the live graph.
Apache NiFi with the ListenHTTP processor receives bundle
submissions and fans them out to the cluster as OpenLineage runs. The ETL
layer is auditable on /enterprise — each run shows up with
its inputs, outputs, and status fields in the lineage overview.
Every successful knowledge import is wrapped in a stats snapshot;
compute_drift() flags entity_dedup_suppressed,
zero_entities_added, entity_count_shrank and similar
regressions. Events surface on the Enterprise dashboard with severity
pills (ok / info / warn / crit) and persist in a Valkey ring
buffer (cap 500). Threshold tunable via DATA_HEALTH_DRIFT_THRESHOLD.
In-page Cypher editor at /explorer with two independent
write-protection layers: a regex blacklist rejecting
CREATE/DELETE/SET/MERGE/REMOVE/DROP/ALTER/GRANT/REVOKE/FOREACH
plus the driver in READ_ACCESS mode. Includes preset queries
and a deep-link to the standalone Neo4j Browser — ad-hoc analysis
with no risk to the live graph.
Embedded JupyterLite (browser-only WebAssembly Python — no server-side
kernel needed) at /notebook alongside five copy-paste snippets
for the orchestrator API (export, pending-import, search, Cypher,
lineage runs). Power users prototype against the live graph without
installing a Python kernel anywhere. JUPYTERLITE_URL
configurable for air-gapped deployments.
Architecture
LangGraph-driven pipeline with parallel expert fan-out, 4-layer caching, and asynchronous Kafka backend.
| Service | Image | Port | Function |
|---|---|---|---|
| LangGraph Orchestrator | Python/FastAPI | 8002 | Main service: API, pipeline, streaming |
| MCP Precision Tools | Python | 8003 | 51 deterministic tools (AST-whitelist) |
| ChromaDB | ChromaDB | 8001 | Vector database for semantic caching |
| Valkey | Valkey | 6379 | Plan cache, performance scores, checkpoints |
| Neo4j | Neo4j 5 Community | 7474/7687 | Knowledge graph for GraphRAG |
| Kafka | Apache Kafka KRaft | 9092 | Event streaming, audit log, feedback loop |
| Prometheus | Prometheus | 9090 | Metrics (API, GPU, containers, host) |
| Grafana | Grafana | 3001 | 5 pre-built monitoring dashboards |
| SearXNG | SearXNG | 8888 | Private meta-search engine without tracking |
| Marquez | OpenLineage | 5000 | Lineage server — inputs/outputs of every pipeline run (optional, Enterprise Stack) |
| lakeFS | lakeFS | 8000 | Git-style versioning of knowledge bundles on MinIO (optional, Enterprise Stack) |
| Apache NiFi | NiFi | 8443 | ETL fan-out via ListenHTTP processor (optional, Enterprise Stack) |
| Tier | Parameters | VRAM (4-bit) | Usage | Escalation |
|---|---|---|---|---|
| T1 | ≤ 20B | 8–16 GB | Fast first opinion, most requests | When CONFIDENCE < 0.65 |
| T2 | > 20B | 16–40 GB | Complex reasoning tasks, low confidence | Endpoint |
ChromaDB vector search
Cosine distance < 0.15 → direct hit
Valkey: planner LLM output
saves ~1,600 tokens per hit
Valkey: Neo4j context queries
avoids redundant graph traversals
Valkey: model ratings per category
Laplace smoothing for routing
MoE Sovereign overcomes the native context window limits of individual models through a three-tier memory architecture. Each tier covers a different time horizon — without additional token costs at inference time.
The last n conversation turns verbatim in the LLM context. Zero loss, instant access, no retrieval overhead.
current sessionEvicted turns are stored as nomic-embed-text vectors (768 dim.) in ChromaDB. Retrieval: direct numpy cosine ranking → topic-overlap fallback → keyword metadata filter. Guaranteed recall at 1M+ stored tokens.
configurable TTLNeo4j knowledge graph: persistently stored facts, entities, and relations. Queried automatically via GraphRAG for knowledge-intensive questions.
New (v2.5): Episodic memory (Tulving 1972; Park et al. 2023) — successful task runs stored as :Episode nodes; routing hints injected for similar future queries.
| System | Native window | Effective window | Privacy | Inference cost |
|---|---|---|---|---|
| GPT-4o (OpenAI) | 128,000 tokens | 128,000 tokens | ☀︎ Cloud | per token |
| Claude 3.5 Sonnet | 200,000 tokens | 200,000 tokens | ☀︎ Cloud | per token |
| Local 7B model (no SM) | 4,000–32,000 tokens | 4,000–32,000 tokens | 🔒 Local | 0 |
| MoE Sovereign + Tier-2 SM | 4,000–32,000 (model) | 1,000,000+ tokens (infra) | 🔒 Local | 0 |
The MRCR-lite v2 benchmark injects facts ("needles") into a synthetic conversation and forces them out of the LLM context via filler turns. The only variable: ChromaDB pre-seeded (WITH) or empty (WITHOUT).
| Depth (filler turns) | WITHOUT Semantic Memory | WITH Semantic Memory | Status |
|---|---|---|---|
| 5 | 0.000 | 1.000 | ✓ Benchmark confirmed |
| 10 | 0.000 | 1.000 | ✓ Benchmark confirmed |
| 20 | 0.000 | 1.000 | ✓ Benchmark confirmed |
| 50–100 | 0.000 | ~1.000 | Retrieval unit test ✓ (rank #1, dist. 0.34) |
60 runs: 5 needles × 3 depths × 2 conditions × 2 reps. Overall WITH score: 1.000.
| Category | Direct | MoE | Overhead factor |
|---|---|---|---|
| Knowledge | ~4,640 | ~29,450 | 6.35× ← lowest |
| Coding | ~1,880 | ~18,950 | 10.36× |
| Math | ~1,270 | ~15,400 | 12.48× |
| Reasoning | ~1,750 | ~16,000 | 14.76× |
| Instruction following | ~460 | ~18,700 | 42.66× |
| Overall | ~2,011 | ~19,844 | 17.32× |
Fixed prompt cost of the MoE cycle: constant ~11,000 tokens per request.
Recommendation: MoE pipeline for knowledge-intensive queries; native mode
(moe_mode: native) for short, simple questions.
| Mode | Overhead | Strengths | Weaknesses | Best for |
|---|---|---|---|---|
native | 1× | Minimal latency, zero overhead, instant response | No memory, no multi-expert, no tools | Short questions, calculations, quick lookups |
moe_orchestrated | 6–43× (avg 17×) | Multi-expert synthesis, MCP tools, GraphRAG, self-correction | High token overhead; poor ROI for simple queries | Complex, cross-domain questions; research; code review |
moe + Semantic Memory | 17× + ~50ms | Long-term memory across sessions; depth 5–20+ at 1.0 recall | Embedding warm-up needed; ~50ms retrieval overhead | Project assistance, support, multi-session research |
moe + Cross-Session | 17× + ~50ms | Shared team knowledge; institutional memory; scope hierarchy | Explicit sharing required; privacy setup needed | Knowledge management, shared project spaces, support teams |
Architecture decisions, bug reports and API discussions from past sessions are retrieved automatically during code reviews. "Why did we choose PostgreSQL over MongoDB?" — answered immediately.
Overhead: 10.36×Team members share research results and findings. What person A discovered last week can be retrieved by person B today via cross-session — no repeated research. Lowest overhead factor.
Overhead: 6.35×In follow-up conversations with the same customer, the system remembers previous solutions, preferences and agreements. No need to re-explain context at the start of each new session.
Overhead: 6–15×Weeks of research accumulate. Hypotheses, sources and interim results from session 1 are still retrievable in session 20 — the system keeps thinking where a human would have stopped.
Overhead: 6.35–12×Tier-2 Semantic Memory is fully OpenAI API-compatible. No client code changes are required — Open WebUI, Claude Code, and any OpenAI SDK client benefit automatically. Enable per template in the Admin UI:
{
"enable_semantic_memory": true,
"semantic_memory_n_results": 8,
"semantic_memory_ttl_hours": 168,
"enable_cross_session_memory": true,
"cross_session_scopes": ["private", "team"]
}Expert System
Each expert domain is fully configurable via the Admin UI — assign any LLM, set system prompts, define tier strategy and GPU node. No code changes required.
| Category | Tier Strategy | Use Case | Special Features |
|---|---|---|---|
| general | T2 | General knowledge, definitions, explanations | — |
| math | T1+T2 | Calculations, equations, statistics | MCP tools + SymPy |
| technical_support | T1+T2 | IT, DevOps, Docker, networking, Linux | MCP network tools |
| code_reviewer | T2 | Code review, security, refactoring | OWASP-focused |
| creative_writer | T2 | Content creation, marketing, storytelling | — |
| medical_consult | T1+T2 | Medical information (not professional advice) | Critic node |
| legal_advisor | T2 | Legal research (not professional advice) | MCP law tools |
| translation | T2 | Professional translation (multilingual) | — |
| data_analyst | T1 | Statistics, data analysis, SQL | MCP stats |
| science | T2 | Chemistry, biology, physics | — |
| reasoning | T1+T2 | Complex logic, strategy, analysis | Thinking node |
| vision | T2 | Image and screenshot analysis | Multimodal |
| agentic_coder | T2 | Autonomous code generation | Full-file output |
| web_researcher | T1 | Web research via SearXNG | Real-time search |
| tool_expert | T1 | MCP tool orchestration | 51 tools |
All expert assignments (LLM model, GPU node, system prompt, tier) are
configured via Expert Templates in the Admin UI or via
the EXPERT_TEMPLATES environment variable. See the
Templating Guide.
Each expert returns a confidence score alongside its response. This determines whether the result is used directly or escalated to a more capable Tier-2 model:
| Model ID | Mode | Description |
|---|---|---|
moe-orchestrator | Standard | Full answers with explanations |
moe-orchestrator-code | Code | Code output only, no prose |
moe-orchestrator-concise | Concise | Max 120 words, no filler text |
moe-orchestrator-research | Research | Deep analysis with source references |
moe-orchestrator-report | Report | Structured report with sections |
moe-orchestrator-agent | Agent | Tool-use optimized for agents |
moe-orchestrator-agent-orchestrated | Agent MoE | Claude Code with full MoE fan-out |
moe-orchestrator-plan | Plan | Task planning with step list |
MCP Precision Tools
LLMs hallucinate on calculations, date arithmetic, and legal statutes. 51 MCP Precision Tools with AST-whitelist security replace these with exact, verifiable results — 100% accuracy, zero variance.
calculate – Safe arithmetic evaluationsolve_equation – SymPy equation solverprime_factorize – Prime factorizationgcd_lcm – Greatest common divisor / LCMroman_numeral – Arabic ↔ Romandate_diff – Difference between datesdate_add – Add/subtract from dateday_of_week – Calculate day of weekunit_convert – km, miles, kg, lb, °C, °F, ...statistics_calc – Mean, median, std dev, percentileshash_text – MD5, SHA-256, SHA-512base64_codec – Base64 encode/decodesubnet_calc – CIDR analysis, netmask, broadcastregex_extract – Apply regular expressionstext_analyze – Word count, chars, sentencesjson_query – JSONPath extractionlegal_search_laws – Search statuteslegal_get_law_overview – Law overviewlegal_get_paragraph – Retrieve paragraphslegal_fulltext_search – Full-text search (BGB, StGB, ...)Getting Started
MoE Sovereign runs on any hardware with Docker — from a single VM to a multi-node GPU cluster. The orchestrator itself needs no GPU; It requires no GPU and no VRAM; inference is handled by external backends (e.g. self-hosted GPU nodes or cloud APIs).
deploy/lxc/setup.shdocker compose up -dhelm install moe charts/moe-sovereignOne OCI Image, Three Profiles: The same container image runs across all deployment targets. Only the environment and surrounding wrapper differ — no code forks, no feature loss. VRAM-aware scheduling automatically distributes models across heterogeneous GPU nodes based on configurable per-node VRAM limits.
curl -sSL https://raw.githubusercontent.com/h3rb3rn/moe-sovereign/main/install.sh | bash
System Monitoring
The built-in monitoring dashboard provides real-time metrics at a glance: active sessions, LLM server status across all GPU nodes, token usage per model, cache hit rate, expert call distribution, and user ratings.

API & Integration
MoE Sovereign behaves like the OpenAI API and additionally supports the Anthropic Messages API. Every existing integration works without code changes.
curl -X POST https://api.moe-sovereign.org/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-API-KEY>" \
-d '{
"model": "moe-orchestrator",
"messages": [
{"role": "user", "content": "Explain the difference between TCP and UDP"}
],
"stream": false
}'curl -X POST https://api.moe-sovereign.org/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-API-KEY>" \
-d '{
"model": "moe-orchestrator-code",
"messages": [{"role": "user", "content": "Write a Python Fibonacci function"}],
"stream": true
}'from openai import OpenAI
client = OpenAI(
base_url="https://api.moe-sovereign.org/v1",
api_key="<YOUR-API-KEY>"
)
response = client.chat.completions.create(
model="moe-orchestrator-research",
messages=[{"role": "user", "content": "Analyze the pros and cons of Kubernetes"}]
)
print(response.choices[0].message.content)# MoE API as Anthropic backend for Claude Code
export ANTHROPIC_BASE_URL=https://api.moe-sovereign.org
export ANTHROPIC_API_KEY=<YOUR-API-KEY>Full API reference, authentication, budget management, and integration guides in the documentation: docs.moe-sovereign.org ↗
Federation
What if independent AI systems could learn from each other without giving up their autonomy? MoE Libris makes this possible — a federation hub inspired by the Fediverse (Mastodon, Friendica), where sovereign MoE instances voluntarily share knowledge graph entries as JSON-LD bundles. No central authority, no forced synchronization. Each node decides what to publish and what to accept.
MoE Libris follows a hub-and-spoke architecture. Each MoE Sovereign instance runs its own Libris node, which connects to federation partners through a bilateral handshake protocol — both sides must explicitly agree before any data flows. Nodes discover each other through a public Git registry (anyone can register via pull request), keeping discovery decentralized and transparent.
The push/pull cycle works as follows: a node curates knowledge graph triples from its local Neo4j database, packages them as JSON-LD bundles, runs them through a pre-audit pipeline (syntax validation + heuristic scanning for PII and secrets), and pushes them to federation partners. On the receiving side, incoming bundles land in an admin audit queue where every entry requires explicit approval before integration into the local knowledge graph.
This solves concrete problems: data silos between isolated AI deployments, vendor lock-in from proprietary knowledge stores, and the cold-start problem for new installations. A fresh MoE Sovereign deployment can import curated knowledge from the federation and immediately benefit from the collective experience of the network — while keeping full control over what enters its own knowledge base.
Imported triples are never treated as first-class local knowledge. They enter at a configurable trust floor and must accumulate confirmation through local usage before their trust score rises. When an imported triple contradicts an existing local triple, the system flags the contradiction for admin review rather than silently overwriting. This prevents knowledge poisoning while still allowing the network to grow.
Data format: Knowledge entries are serialized as JSON-LD triples (subject-predicate-object) with provenance metadata, timestamps, and trust scores attached. The format is self-describing and interoperable with standard RDF tooling.
Pre-audit pipeline: Before export, every bundle passes through two stages: (1) syntax validation ensuring well-formed JSON-LD and valid triple structure, and (2) heuristic scanning that flags potential PII (names, emails, addresses), API keys, credentials, and sensitive relation types. Flagged entries are held for manual review.
Abuse prevention: The federation implements a graduated strike system. Nodes that repeatedly push low-quality, flagged, or rejected content accumulate strikes. Thresholds trigger rate limiting, temporary suspension, and eventually permanent exclusion from the federation — all enforced locally by each receiving node.
Stack: FastAPI for the federation API, PostgreSQL for federation state and audit logs, Neo4j for the global knowledge graph, Valkey for caching and rate limiting. The entire stack runs in Docker containers alongside the main MoE Sovereign deployment.
Compliance Layer — Open Source
95 % of operators want a sovereign LLM gateway — that’s MoE Sovereign. The remaining 5 % in regulated sectors need documented risk classification, data lineage, approval workflows, and audit trails. That’s MoE Codex — an open-source extension layer architecturally inspired by platforms like Palantir Foundry, without claiming their commercial maturity or enterprise depth.
MoE Codex is an opt-in extension layer deployed alongside a running MoE Sovereign instance. It adds a full data management stack on top of the LLM gateway:
MoE Codex was designed with current EU regulations in mind: EU AI Act (Reg. 2024/1689) — high-risk Annex III systems require risk documentation and audit trails; MoE Codex provides both. NIS2 / NIS2UmsuCG — risk management and supply-chain transparency for essential entities. GDPR Art. 35 DPIA — catalog metadata and lineage records document processing activities. BSI Grundschutz & C5 — hosting on BSI-C5-certified EU providers (Hetzner, IONOS, STACKIT, OVHcloud).
The BVerfG 2023 judgment (Hessendata = Palantir Gotham ruled unconstitutional) created an acute need for sovereignly deployable, technically auditable data platforms across the EU. MoE Codex addresses exactly this need as an open-source approach: Apache 2.0, air-gap capable, fully auditable codebase, zero US-cloud dependency, zero vendor lock-in.
Honest positioning: MoE Codex is not a current drop-in replacement for Palantir Foundry in terms of product maturity, enterprise support, or certification depth. It is an architecturally related, transparent open-source platform — with the potential to become a credible long-term alternative in regulated scenarios where auditability and data sovereignty outweigh commercial feature breadth.
Compliance
MoE Sovereign and MoE Codex implement technical safeguards that map directly to active information security standards. Here is how the stack supports auditing.
| Annex A Control | Status | Technical Mechanism | Operator Responsibility |
|---|---|---|---|
| A.5.9 / A.5.12 Asset & Info Classification |
Prepared | Metadata registry in the Data Catalog with automated GDPR classification and retention tags. | Define organizational data classification guidelines. |
| A.8.2 / A.8.3 Access Control |
Operational | Attribute-based access control (ABAC) enforced via Open Policy Agent (OPA) Rego policies. | Integrate central Identity Provider (LDAP/OIDC). |
| A.8.12 Data Leakage Prevention |
Operational | Local-first air-gap deployment; outbound policy filters in federation/ block critical domains. |
Configure network perimeter firewall and DLP logs. |
| A.8.16 Logging & Monitoring |
Operational | Auditable OpenLineage metadata flows captured by Marquez; Prometheus telemetry for hosts/containers. | Integrate with corporate SIEM and alert escalation rules. |
| A.8.20 / A.8.22 Network Security |
Prepared | Isolated bridge networks in Docker Compose; containerized model runtimes (LXC/Podman). | Configure hardware-level VLAN routing and network segmentation. |
| A.8.25 / A.8.28 Secure Development & Change |
Operational | Git-style branching, commits, and bundle approval workflows on lakeFS. | Establish secure SDLC policies and code review guidelines. |
A software stack alone cannot obtain an ISO 27001 certificate, as audits cover organizational policies, employee awareness, and physical facility security. MoE Sovereign and MoE Codex provide the technical framework and evidence logs to significantly accelerate your organization's certification path, but full compliance requires the operator to establish the necessary organizational controls.
Project Status
MoE Sovereign reached its public release on April 13, 2026. All four launch phases are complete. Development continues with community contributions and federated knowledge features.
Docker Compose, LXC, Podman, and Helm deployment wrappers. VRAM-aware scheduling across heterogeneous GPU clusters. Prometheus, Grafana, and Kafka observability stack.
LangGraph pipeline with two-tier expert escalation, 51 MCP precision tools, Neo4j GraphRAG with trust-score self-healing, 4-layer cache hierarchy, complexity routing, and self-correction loop.
69-model LLM suitability study, 15 expert domains, 6 Claude Code profiles, GAIA L1 benchmark (60%), 9.3× compounding effect validated, adversarial MCP testing (9/9 blocked). AIHUB H200 benchmark: 9/9 passed (100%) with gpt-oss-120B + qwen-3.5-122B. M10-Gremium 8-expert template: 9/9 passed on legacy hardware. GAIA Benchmark: 14/30 = 46.7 % — surpasses GPT-4o Mini (44.8 %). 5 iterative runs (2026-04-25): L1 60 %, L2 50 %, L3 40 % (best run). 8 new deterministic MCP tools: wikidata_sparql, pubmed_search, crossref_lookup, openalex_search, web_browser, wayback_fetch. Thompson Sampling (RL flywheel), Correction Memory, Context Window Abstraction Layer.
Published on GitHub under Apache 2.0. Community knowledge bundles with privacy scrubber. Full documentation at docs.moe-sovereign.org. Whitepapers (EN/DE) and presentation published. IEEE paper prepared for arXiv submission. Technical addendum (April 2026): 1M-Token Context Window → measurements, comparisons, compatibility.
Three new peer-reviewed additions to the GraphRAG layer (v2.5.0):
Corrective RAG Gate (Yan et al., arXiv:2401.15884) — per-entity relevance scoring before context injection, prevents context pollution;
CAG Compliance Layer (Chan et al., arXiv:2412.15605) — BAIT/VAIT/DORA/KRITIS texts injected deterministically from admin JSON files, bypassing Neo4j for stable regulatory domains;
Episodic Memory (Tulving 1972; Park et al. arXiv:2304.03442; Packer et al. arXiv:2310.08560) — successful task runs stored as :Episode nodes in Neo4j with routing hints for similar future queries.
All three are fire-and-forget, zero latency overhead, and fully opt-out via env vars.
Effective 1M-token context window through infrastructure rather than
model upgrades: evicted conversation turns are stored as nomic-embed-text
vectors (768 dim.) in ChromaDB and retrieved on demand via hybrid retrieval
(direct cosine ranking + keyword fallback). Template flag enable_semantic_memory: true
activates Tier-2 for any expert template with no additional token cost at inference time.
Validated by MRCR-lite v2 benchmark (needle recall at depths 5–100) —
overall score 1.000; full benchmark results in the
context window documentation.
Proposal EHPC-DEV-2026D06-XXX approved by EuroHPC: award notice received on June 5, 2026. 4,500 node-hours (equivalent to 18,000 GPU-hours) on the LUMI-G supercomputer (AMD MI250X, 128 GB HBM2e per node, ROCm stack, 2 TB storage), 6-month duration. The grant funds a distillation research programme that moves central routing and planning components from cloud LLMs to locally runnable Small Language Models — another step towards full digital sovereignty without cloud dependence.
Current research under the LUMI-G grant: five distillation targets — the
planner_node (primary lever, targeting granite4.1:3b as
GGUF Q4_K_M / Q5_K_M, ≥90% of the 35B teacher model's
GAIA plan quality at roughly 1/10th the cost), a complexity_estimator
(DeBERTa-v3-small, ONNX INT8), a semantic router (multilingual MiniLM encoder +
FAISS), an RL routing policy (offline RL, MLP) and a node ranker (XGBoost, ONNX).
The 6-month plan covers synthetic data generation, encoder/reward-model training,
SFT+DPO for the planner, offline RL and a final RLHF pass. In parallel, the
knowledge graph is growing rapidly (×46 entities / ×56 relations in
16 days) — the next milestone is the first multi-hub MoE Libris federation.
License: Apache 2.0 · Stack: Python + FastAPI + LangGraph · Minimum hardware: no VRAM – inference via external API backends
Screenshots
Live screenshots from production operation — Admin UI, live monitoring, Grafana dashboards, container logs, and knowledge graph.
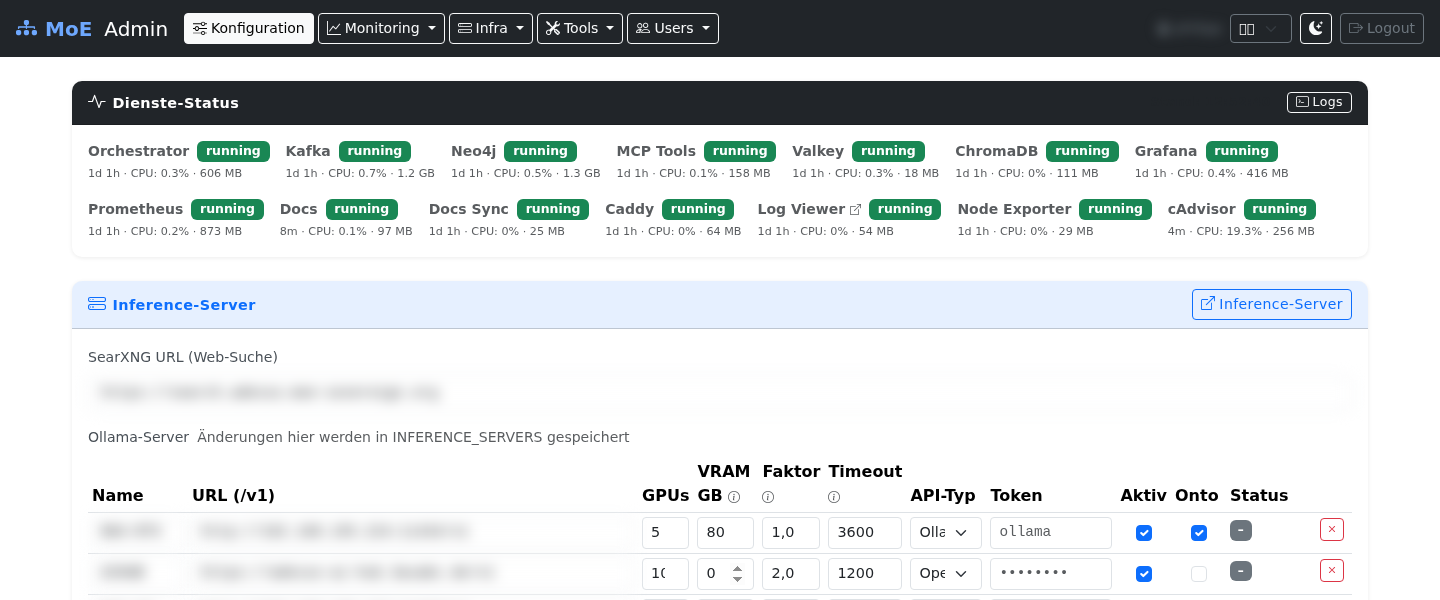
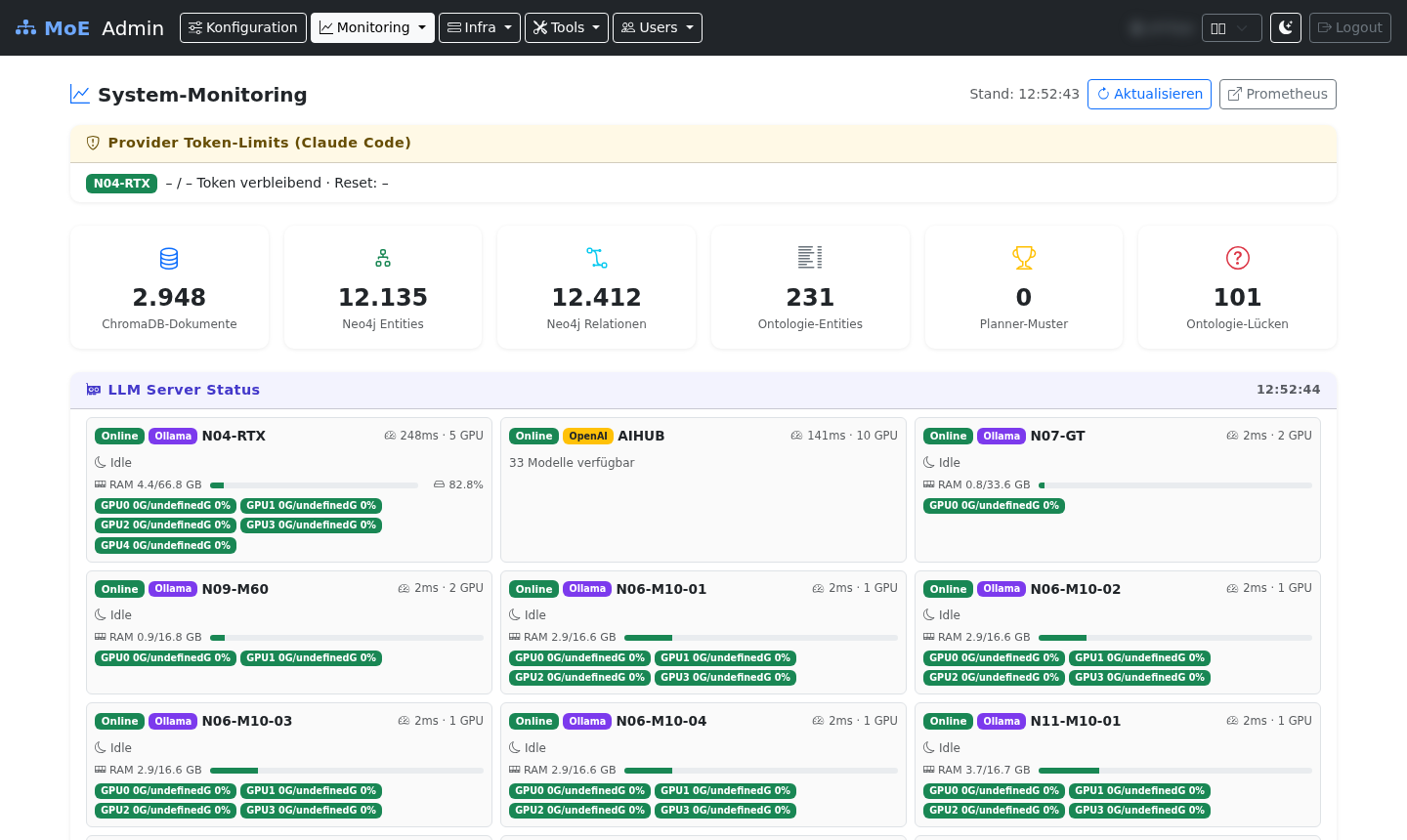
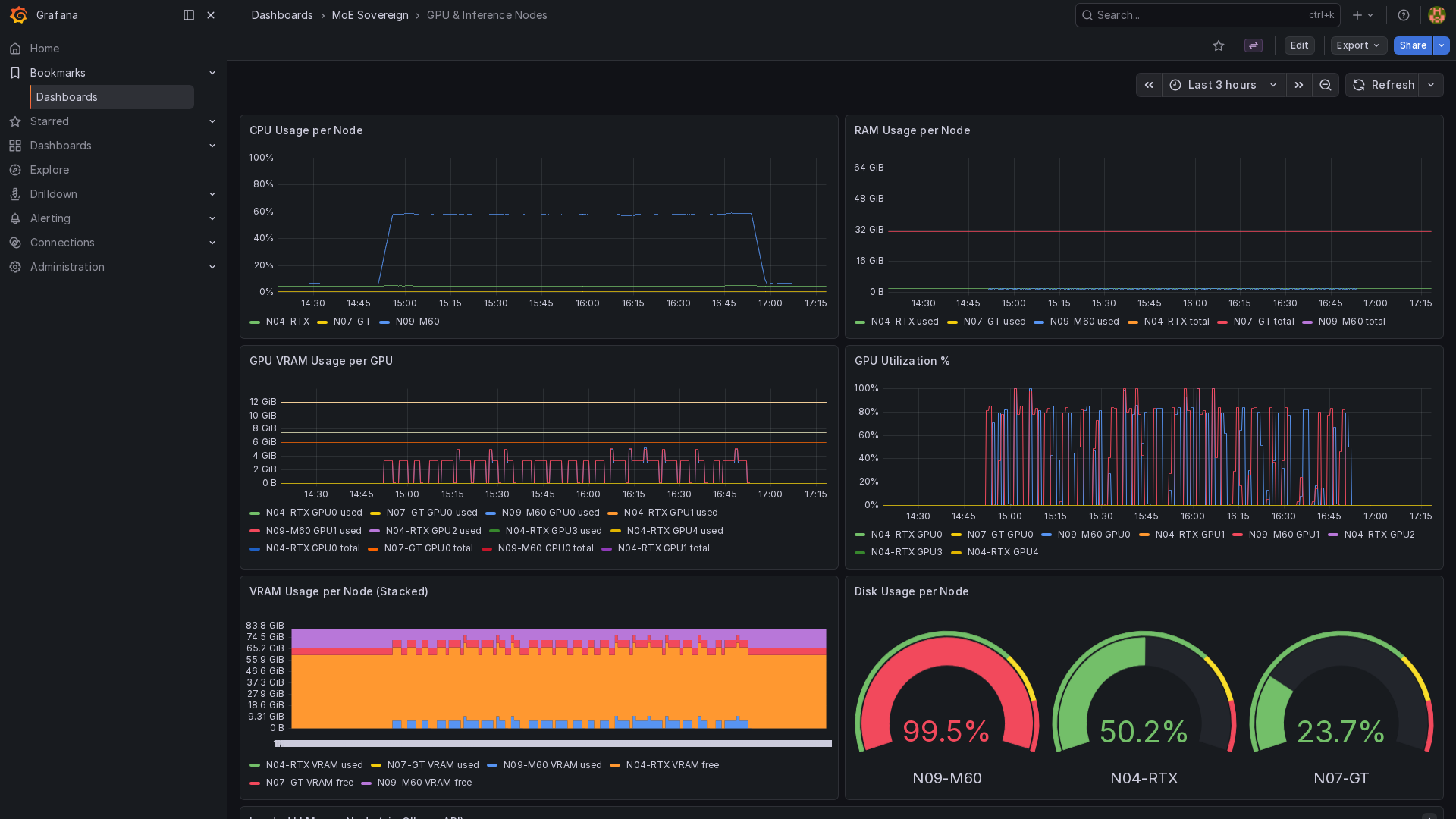

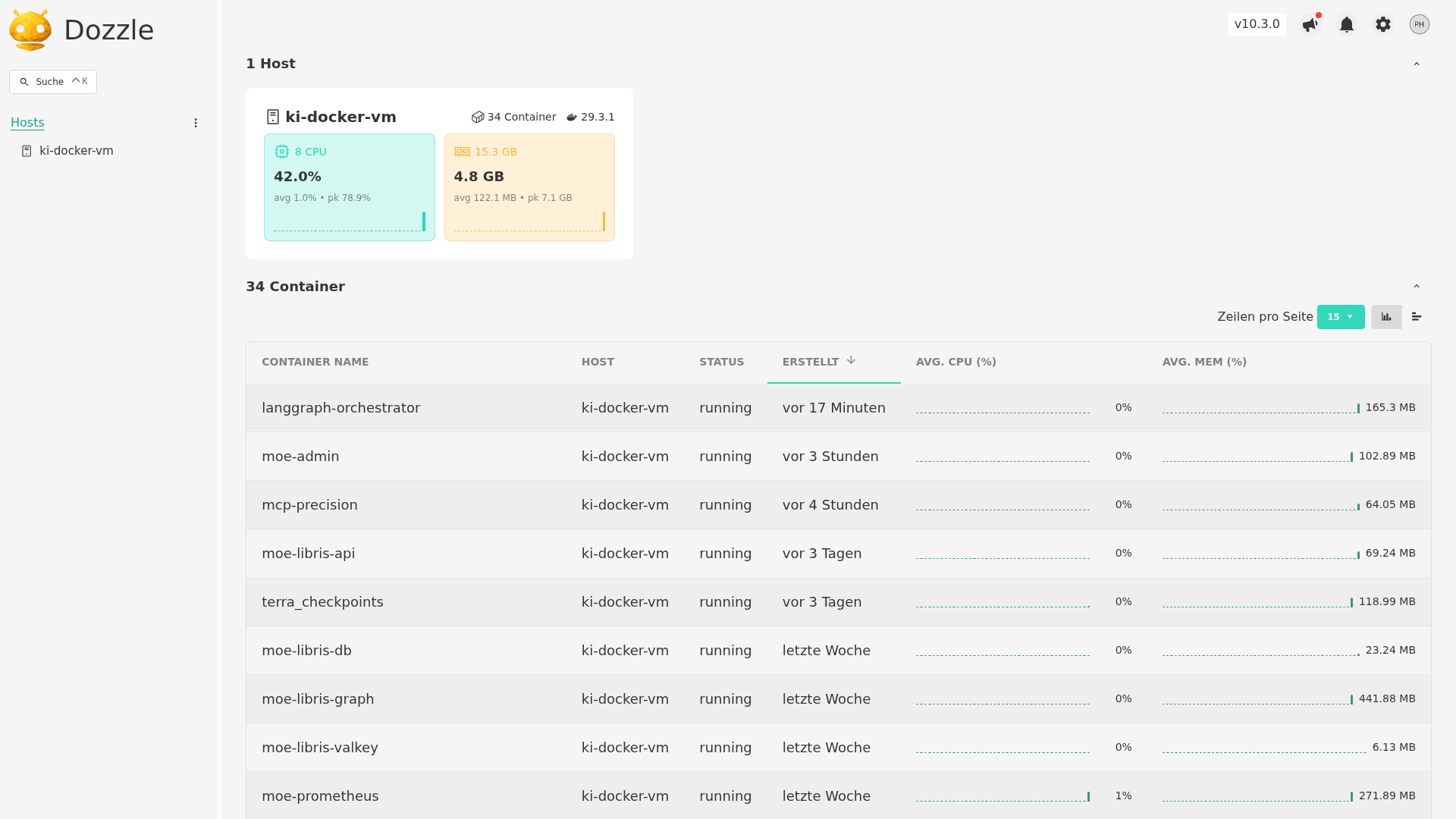

Platform Architecture
MoE Sovereign is the core — a fully self-hosted LLM gateway with expert routing, GraphRAG, and MCP precision tools. Two optional extensions complete the platform: MoE Codex adds enterprise data intelligence, and MoE Libris enables federated knowledge exchange between sovereign deployments.
The centre of the stack. Template-based multi-model orchestrator with 15 specialist experts, 51 deterministic MCP tools, Neo4j GraphRAG, 4-layer caching, Kafka event streaming, and a 1 million-token semantic memory layer. Runs air-gap ready on any Linux host. Zero mandatory cloud calls.
API: OpenAI-compatible + Anthropic Messages API · Port: 8002
Optional add-on for regulated sectors. Extends the core with a full Palantir Foundry-inspired data management stack — all open source, all deployable alongside MoE Sovereign without touching its configuration.
Coverage: 92 % of Palantir Foundry/Gotham/AIP surface area · Apache 2.0
Optional federation layer. Independent sovereign deployments exchange curated knowledge graph bundles via a Fediverse-inspired hub-and-spoke protocol. Bilateral consent handshake, pre-audit PII pipeline, trust-scored imports, and admin approval queue — no central authority, no forced synchronisation.
Protocol: JSON-LD triples with provenance · Anti-poison: conflict detection + strike system
| Layer | Role | Interfaces with | Required |
|---|---|---|---|
| MoE Sovereign | LLM gateway, expert routing, GraphRAG, MCP tools | Clients via OpenAI / Anthropic API, Codex via REST, Libris via bundle import | Yes — core platform |
| MoE Codex | Data catalog, lineage, versioning, BI, investigation, compliance | Receives OpenLineage events from Sovereign; writes approved bundles back to Neo4j | Optional — regulated deployments |
| MoE Libris | Federated knowledge exchange between sovereign instances | Sends / receives JSON-LD bundles; imports land in Codex approval queue | Optional — multi-cluster deployments |
Deploy Sovereign for citizen-query routing and legal-advisor expert. Add Codex for EU AI Act audit trails, NIS2 risk documentation, and the OPA policy layer that enforces classification markings. Use lakeFS to snapshot evidence datasets before every decision run.
Sovereign handles medical consultation routing and document analysis via DocLing. Codex tracks clinical trial dataset versions in lakeFS, records full provenance in Marquez, and surfaces compliance gaps in Superset dashboards connected to Trino’s federated SQL layer.
Route model-risk and regulatory queries through Sovereign’s expert ensemble. Codex delivers the complete audit trail required under DSGVO Art. 35 and BSI C5: OpenLineage lineage from source to inference output, lakeFS dataset commits, OPA policy decisions, and Superset compliance dashboards. OpenSearch enables cross-system investigations without data movement.